Le 5 avril 2025, Meta a frappé fort en dévoilant les premiers modèles de sa série Llama 4, conçus pour être nativement multimodaux. Leurs noms ? Scout et Maverick. Ils seront bientôt rejoints par le géant Behemoth, encore en développement. Ces trois modèles montrent une volonté claire de Meta : fournir des modèles ouverts, performants, et optimisés pour les usages professionnels, des alternatives puissantes face à d’autres géants comme OpenAI et Google.
Derrière cette annonce se cache la promesse d’une technologie de pointe dans le domaine de la génération de contenus à grande échelle, notamment texte, image et vidéo, reposant sur une architecture Mixture-of-Experts (MoE), capable d’allier puissance de traitement, modularité, et coût optimisé. Mais qu’en est-il réellement, au-delà de l’effet d’annonce ? Les performances promises sont-elles au rendez-vous ? Pour vous, LabSense fait le point dans cette analyse. 🔬
3 nouveaux modèles pour la version 4 de Llama
⚡ Scout : le modèle compact et ultra-mémoriel
Avec 109 milliards de paramètres totaux répartis sur 16 experts, Scout est le plus léger de la série Llama 4 et se veut l’allié des synthèses complexes et du traitement massif. Son atout majeur ? Une fenêtre de contexte de 10 millions de tokens, un record dans l’industrie, contre 128 000 pour Llama 3. Cela ouvre la porte à :
- La synthèse multi-document à grande échelle
- L’analyse détaillée de l’activité utilisateur
- La compréhension profonde de bases de code volumineuses
🖥️ Scout fonctionne sur un seul GPU Nvidia H100, ce qui le rend idéal pour les entreprises aux ressources techniques limitées. Attention, avec quantification Int4, le prix de ce composant professionnel avoisine les 30 000 euros !
🧩 Maverick : le modèle généraliste hautement polyvalent
Avec 400 milliards de paramètres, Maverick est plus ambitieux. Conversations, génération, codage… cet assistant IA tout-en-un active également 17 milliards de paramètres par tâche, mais répartis sur 128 experts, ce qui le rend plus précis et plus robuste. Sa fenêtre contextuelle de 1 million de tokens lui permet de :
- Servir d’assistant multilingue et culturellement pertinent
- Comprendre et extraire des données structurées de PDF ou formulaires
- Aider à la génération créative (histoires, marketing, contenu SEO)
🖥️ Idéalement, Maverick fonctionne sur un système DGX H100, mais pourrait tourner sur des stations comme le Mac Studio M3 Ultra dans certaines configurations.
🦾 Behemoth : le géant en incubation
Llama 4 Behemoth est le troisième modèle annoncé et le plus puissant développé par Meta à ce jour, mais est encore en phase de développement. Ses chiffres donnent pourtant le vertige : 2 trillions de paramètres (au total 288 milliards de paramètres actifs) avec 16 experts. Il serait particulièrement prometteur pour les applications scientifiques, d’ingénierie et d’analyse de données complexes. Entraîné sur plus de 30 000 milliards de tokens, en texte, image et vidéo, il fonctionne sur 32 000 GPU avec FP8 pour un pic de 390 TFLOPs/GPU. Par ailleurs, Behemoth est le modèle enseignant à partir duquel Scout et Maverick ont été distillés.
MoE : l’ingrédient secret derrière la performance et l’efficacité
Meta n’a pas fait les choses à moitié : les trois modèles sont conçus selon l’architecture MoE (Mixture of Experts), qui permet d’activer uniquement les “experts” nécessaires à chaque requête, réduisant la charge tout en augmentant l’efficacité. Et ce qui rendrait cette génération de modèles Llama si singulière, c’est moins le nombre de paramètres que la manière dont ils sont utilisés.
Contrairement aux architectures classiques où tous les neurones sont mobilisés à chaque requête, l’approche MoE sélectionne seulement quelques experts spécialisés pour traiter chaque tâche. Ce serait un peu comme avoir un immense cabinet de spécialistes, mais ne convoquer que deux experts ciblés selon le sujet de la question : un fonctionnement à la fois plus rapide, plus économe, et souvent plus pertinent.
📌 Maverick, par exemple, fait appel à 2 experts parmi 128 pour chaque requête, soit 17 milliards de paramètres actifs — une fraction de son potentiel total.
Cette architecture permettrait à Meta d’atteindre un rare équilibre entre puissance brute et efficacité opérationnelle. Cela explique pourquoi certains modèles comme Scout peuvent tourner sur un seul GPU H100, tout en traitant des contextes allant jusqu’à 10 millions de tokens. En clair : MoE n’est pas juste une optimisation technique. Ces avancées rendraient cette nouvelle génération d’IA, plus accessible, plus spécialisée, et plus durable.
💡 Le saviez-vous ?
Les modèles Allready, la solution IA de LabSense, utilisent les derniers LLM de pointe. Ils peuvent vous aider à gérer vos projets de génération de contenu, qu’il s’agisse d’annonces immobilières, d’articles ou de fiches produits. Les tester, c’est les adopter !
Llama 4 : la promesse de performances titanesques
🥇 Le prodige compact nommé Scout
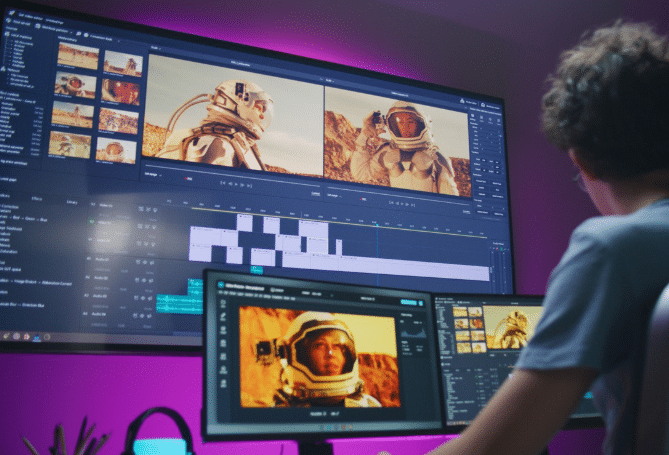
Scout repousserait les limites de l’optimisation. Avec une fenêtre contextuelle record de 10 millions de tokens, il dépasse largement Llama 3 (128 000 tokens). Il surclasserait Gemma 3, Mistral 3.1 et Gemini 2.0 Flash-Lite, notamment dans des tâches comme la synthèse multi-documents ou le raisonnement sur de grandes bases de code.
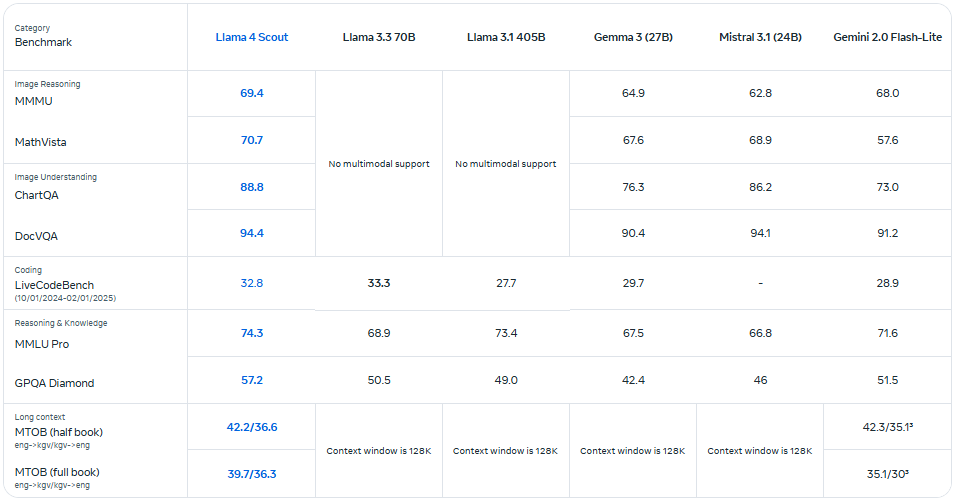
⚖️ Maverick : l’équilibre entre puissance et polyvalence
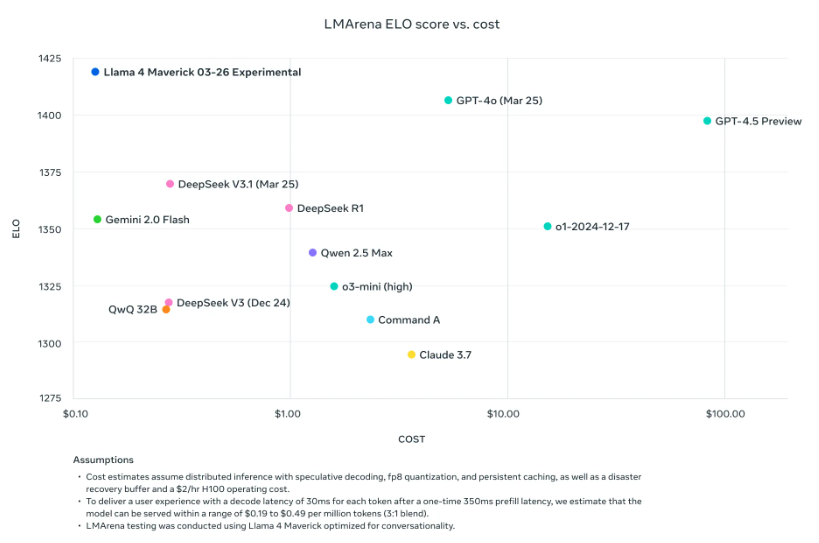
Avec 400 milliards de paramètres et un score ELO de 1417 sur LMArena, Maverick rivaliserait maintenant avec les meilleurs. Il dépasserait GPT-4o, Gemini 2.0 Flash et DeepSeek v3 dans des domaines clés : raisonnement, codage, multilinguisme et même compréhension d’images. Il fonctionne sur DGX H100, mais peut aussi tourner sur des Mac Studio M3 Ultra dans certains cas.
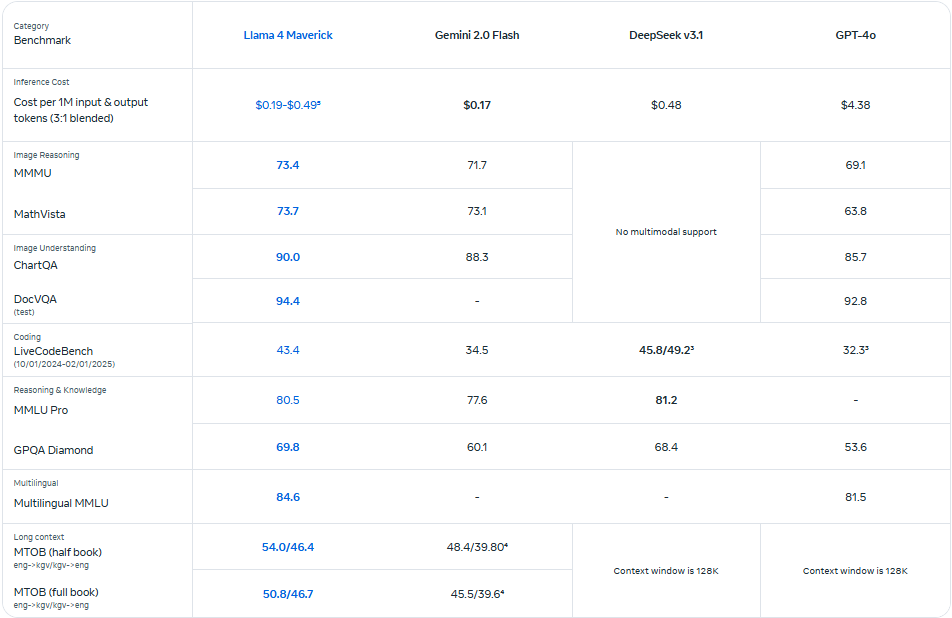
💎 Le diamant brut Behemoth
Quant à Behemoth, ce modèle aux chiffres affolants incarne la démesure. Il surpasserait GPT-4.5, Claude Sonnet 3.7 et Gemini 2.0 Pro sur les benchmarks STEM. Même s’il n’est pas encore affûté pour le raisonnement complexe, ses performances globales sont déjà impressionnantes.
À lire aussi

Gemini passe à la vitesse supérieure : les nouveautés de l’IA multimodale signée Google
« Le 18 mars 2025, Google a frappé fort avec les dernières évolutions de son intelligence artificielle Gemini. Des fonctionnalités inédites viendraient enrichir l’expérience utilisateur, rendant l’IA toujours plus intuitive, … » >> Lire la suite

OpenAI dévoile ChatGPT 4.5 : un modèle puissant, mais transitoire
« Depuis quelques années, l’intelligence artificielle (IA) ne cesse de progresser et d’évoluer, révolutionnant des secteurs variés et modifiant en profondeur la manière dont nous interagissons avec… » >> Lire la suite.

Claude 3.7 Sonnet : comment Anthropic innove pour rivaliser avec OpenAI, xAI et DeepSeek
« La course à l’intelligence artificielle générative prend un nouveau tournant avec le lancement de Claude 3.7 Sonnet par Anthropic. Ce modèle de langage avancé repousse les limites en matière de codage… » >> Lire la suite.
📉 Des utilisateurs finalement déçus ?
Si les retours concernant ces trois nouveaux modèles et leurs performances ont été généralement dithyrambiques à leur sortie, les résultats de benchmarks délivrés par les entreprises elles-mêmes sont néanmoins à prendre avec prudence. Déjà, les professionnels doutent des réelles performances de Llama 4, notamment comparées à celles de la concurrence, à savoir Gemini 2.5 et GPT-4.5. Ces derniers n’ont pas manqué de partager leur mécontentement sur un modèle selon eux annoncé prématurément via quelques exemples concrets de ces résultats décevants, qui semblent d’ailleurs se multiplier sur le net.
Sur les réseaux sociaux, il serait même question de trafic des résultats des benchmarks en interne pour accélérer la sortie de Llama 4 et tenter de faire face à la créativité fulgurante du marché. Il s’agirait donc de voir quelles optimisations Meta compte bientôt apporter à ses modèles, dont le principal atout reste tout de même leur capacité d’ouverture.
Ainsi, l‘architecture MoE présentée par Meta comme une innovation majeure venue avec Llama 4 pourrait avoir été spécifiquement paramétrée pour optimiser les résultats sur les différents benchmarks connus. Quant aux nombreux experts, ils semblent avoir été entraînés pour identifier et réussir sur les problèmes spécifiques aux évaluations standardisées, tandis qu’en conditions réelles, c’est la polyvalence de la machine qui est requise.
Disponibilité et restrictions
Scout et Maverick sont disponibles en téléchargement gratuit sur Llama.com et Hugging Face, mais avec des conditions :
- ces nouveaux modèles sont d’ores et déjà disponibles sur la plateforme Meta AI ainsi que via WhatsApp, Messenger et Instagram Direct dans 40 pays ;
- les fonctionnalités multimodales ne sont actuellement accessibles qu’aux États-Unis et avec des contrôles anglophones ;
- les entreprises dépassant 700 millions d’utilisateurs mensuels doivent demander une autorisation à Meta ;
- l’Europe, soumise à un cadre réglementaire strict, devra patienter ;
- Meta a également assoupli sa modération sur les contenus sensibles, tout en conservant des garde-fous qui restent toutefois non détaillés à ce jour.
Llama 4, un tournant pour les usages professionnels de l’IA
Avec Llama 4, Meta souhaite pousser encore plus loin les limites de l’IA générative multimodale, tout en conservant une certaine ouverture. Véritable tremplin pour l’innovation IA en entreprise, l’architecture MoE permettrait des modèles plus rapides, plus efficaces et adaptés à divers niveaux de puissance matérielle. Des capacités impressionnantes, un positionnement stratégique clair, et des performances qui rivaliseraient (voire dépasseraient) certains des meilleurs modèles du marché : Llama 4 a tout pour s’imposer comme un incontournable dans l’écosystème IA de 2025… mais seulement une fois ses modèles perfectionnés et les évaluations lavées de tout soupçon d’ingérence en interne. Prévenir l’overfitting sera désormais l’un des challenges essentiels en apprentissage et génération automatiques.
🤝 Exploitez le plein potentiel des LLM dans vos projets de contenu
Quelle que soit la nature de votre projet de contenu, LabSense saura vous accompagner ! Avec plus de 10 ans de R&D, 200 clients, et 400 millions de textes générés, notre mission est d’intégrer intelligemment les modèles IA à vos cas d’usage métier, tout en valorisant vos données (open data, météo, clients, produits…).
📩 Contactez-nous dès aujourd’hui pour en discuter : notre équipe d’experts IA est là pour transformer votre contenu en valeur stratégique.
Et vous ?
*Sondage réalisé avec Allready, la plateforme IA de LabSense